
Tempo de Leitura:
Olá, navegante dos dados!!! ⛵📊
Há um tempo atrás eu havia realizado a criação de um post sobre a arquitetura medalhão, mas infelizmente algumas pessoas me alertaram que ficou fora do ar e ele era bastante visualizado… 😦
Massss estou resgatando o mesmo com melhorias e voltando a divulgar agora em meu blog para que todos continuem com acesso e dessa vez não irá mais sumir. hahaha
Ótima leitura!
Sumário
♒Entendendo sobre Lakehouse
Ao pesquisar um pouco sobre esta arquitetura, vamos encontrar alguns artigos falando sobre ela e no site da Databricks temos uma definição simples e bem clara:
“Uma arquitetura medalhão é um padrão de design de dados usado para organizar logicamente os dados em um lakehouse, com o objetivo de melhorar incremental e progressivamente a estrutura e a qualidade dos dados à medida que fluem através de cada camada da arquitetura (das tabelas de camada Bronze ⇒ Silver ⇒ Gold).”
Ok, mas o que seria um Lakehouse?
O conceito Lakehouse nasceu há pouco tempo, sendo um tipo de “unificação” dos conceitos de Data Warehouse + Data Lake e normalmente são bastante confundidos.
Vamos então ver um breve resumo da diferença entre essas arquiteturas:
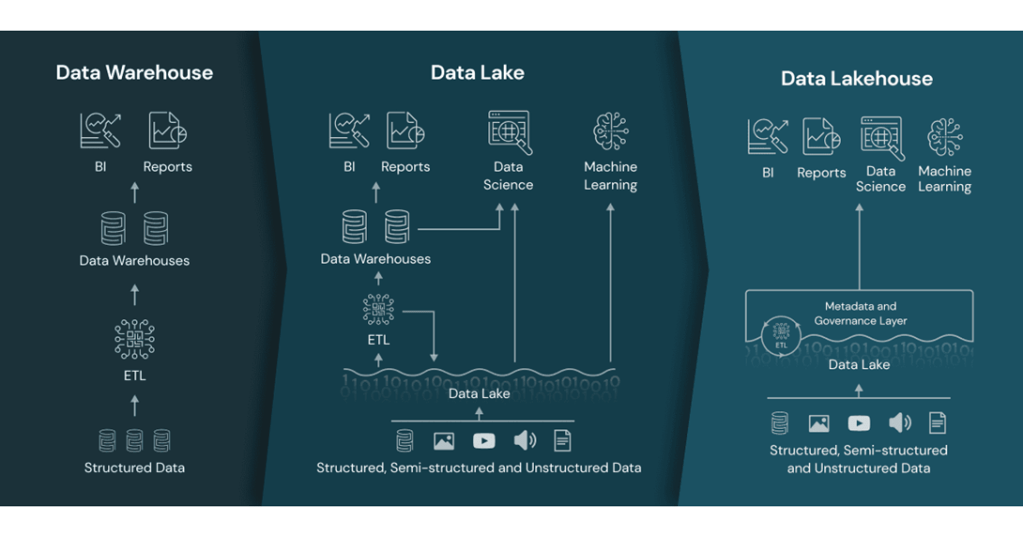
- Data Warehouse: É um repositório de dados analíticos, gerado a partir de dados transacionais (normalmente dados estruturados). Nele utilizamos processos de ETL (extração, transformação e carregamento de dados) e são muito utilizados para Business Intelligence (BI).
Com sua utilização podemos ter alguns problemas como volumetria de dados, estresse do banco de dados, cargas demoradas, não conseguir trabalhar com muitas variações de dados, performance, etc…
- Data Lake: Após o “boom” do avanço da internet e suas tecnologias, surgiu então a necessidade de analisar essas novas variedades de dados e conseguir acompanhar a sua volumetria. Surge então um novo conceito de repositório de dados desenhado para armazenar e processar grandes quantidades de dados estruturados e não estruturados (vídeos, imagens, documentos, Comentários de usuários em blogs e sites de rede social, …).
Tem como fonte da verdade os dados a partir do seu formato bruto. Nele utilizamos processo de ELT e são muito utilizados por cientistas de dados e analistas de BI.
Com sua utilização podemos ter alguns problemas como consistência de dados, pois não há controle ACID; onde por exemplo, se tivermos algum job em execução e o mesmo apresentar um problema no meio de sua execução, os dados ficam inconsistentes pois não há controle de Rollback. Não existe controle de versionamento ou auditoria por logs; operações de delete, atualização e merge não são fáceis e existe muito uso de ETL do data lake para um DW.
Entendendo os problemas com as duas arquiteturas anteriores, surge então o Data Lakehouse, que seria a ideia de trazer o Data Warehouse para dentro do Data Lake, porém adicionando uma governança unificada e facilidade na movimentação dos dados. Utilizando por exemplo as features do Delta Lake (que é um projeto de código aberto), que fornece transações ACID para o Apache Spark, manipulação de metadados, processamento de dados em streaming e batch em data lakes como o ADLS, S3, GCS, HDFS… Unindo assim, o melhor das duas arquiteturas anteriores em um único repositório, porém com maior poder de processamento, escalabilidade, e confiabilidade em relação aos dados.
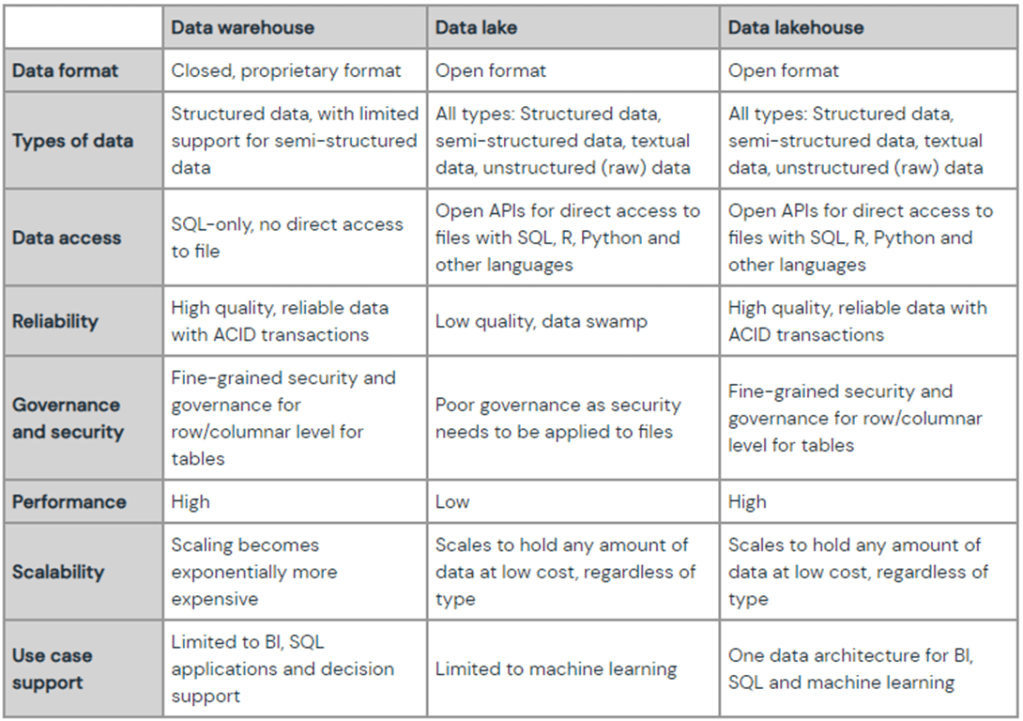
Abaixo, uma ótima comparação entre Data Warehouse, Data Lake e Data Lakehouse que está disponibilizada aqui no site da Databricks:
Uma vez que entendemos então a definição de um lakehouse, quais seriam os benefícios de trabalhar com este tipo de arquitetura e qual seria a melhor forma de implantá-lo na sua organização? Neste momento surgem “N” pensamentos sobre o que seria “a verdade” em termos de padronização e boas práticas, mas veremos ao longo do artigo que muito do que precisará ser feito vai depender de negócio para negócio. Logo, não teríamos então algo como 100% fonte da verdade, pois em um projeto de Big Data sempre vamos ter que lidar com muitos conceitos e que, independentemente das ferramentas utilizadas, nada irá vir pronto, você sempre irá analisar o cenário e aplicar tecnologias, ferramentas e conceitos conforme necessidade e viabilidade para seu projeto.
🏅Conhecendo a Arquitetura Medalhão
Quando estamos trabalhando em um projeto de Big Data, irá aparecer situações em que não iremos ter definições exatas e irá ser preciso um pouco mais de paciência e reflexão. Uma dessas questões é como organizar as informações no Data Lake, pois se as informações não estiverem organizadas da maneira correta, elas podem se tornar inúteis (transformando-se em um data swamp) ou até mesmo prejudicar a análise dos dados no dia a dia. Por isso, é importante pensar bem na estrutura do Data Lake para garantir que as informações estejam disponíveis e acessíveis quando precisarmos delas.
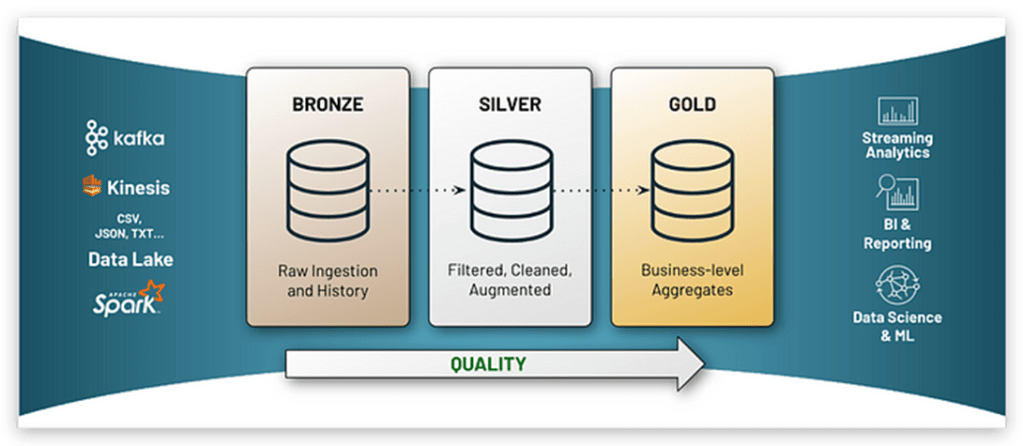
A “Arquitetura Medalhão” visa realizar essa organização dentro do repositório, distribuindo os dados em várias camadas/níveis diferentes e que ao mesmo tempo possam atender necessidades diferentes do negócio, mantendo o ambiente seguro, organizado e de fácil compreensão.
Iremos falar um pouco sobre as camadas Bronze, Silver e Gold, mas primeiramente, vamos falar sobre uma camada importante que antecede as demais.
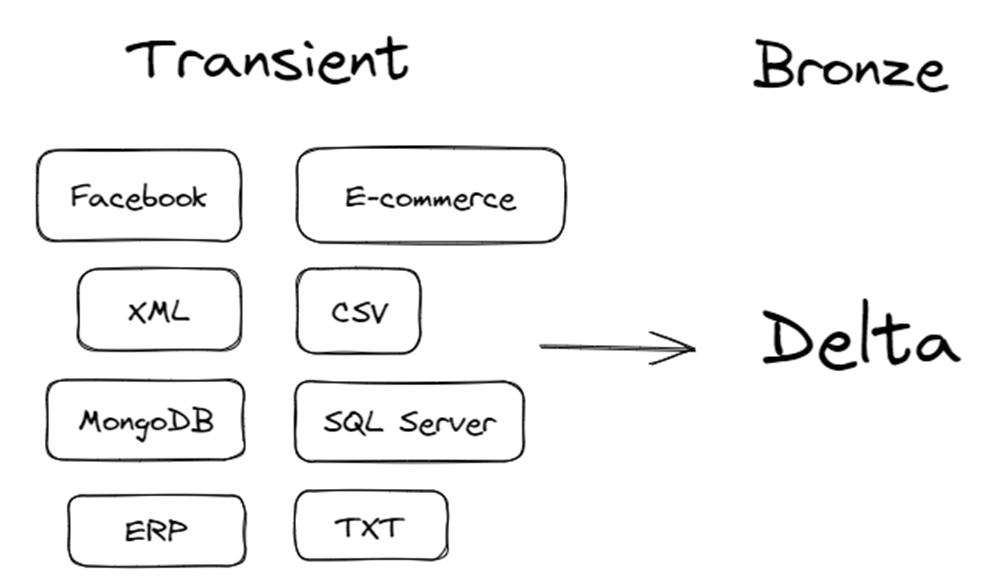
🔄 Transient (landing)
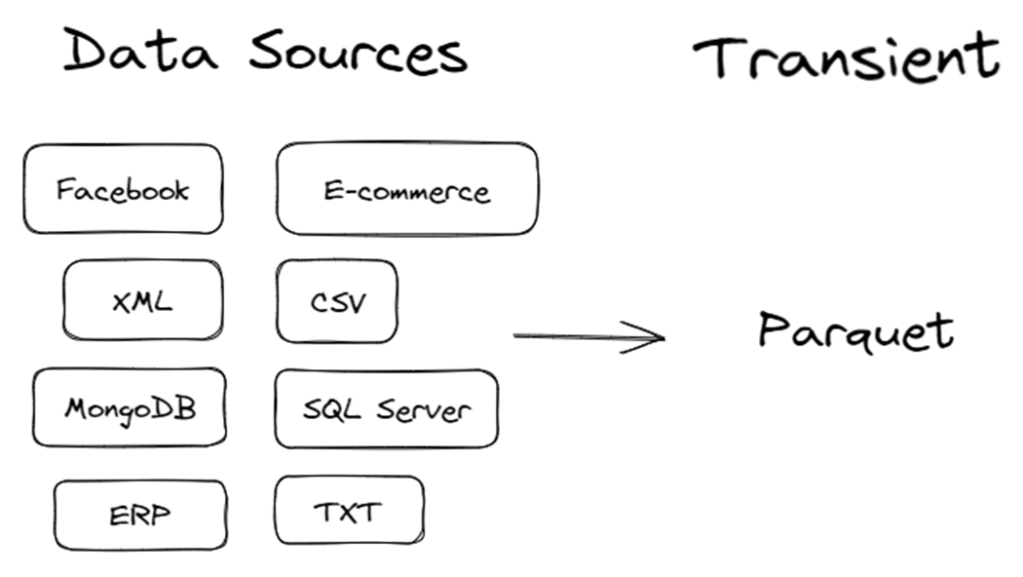
É uma camada de staging, responsável pela primeira ingestão dos dados no data lake. É um local onde diferentes variações de dados e arquivos (RDBMS, XMl, CSV, JSON…), de diversos sistemas e fontes de origem (ERP, WMS, E-commerce, Redes Sociais, IoT, etc…) serão armazenados antes de movê-los para a camada Bronze(raw).
Ela é extremamente útil para uma primeira organização dos dados em relação as fontes, onde ao realizar a ingestão desses dados, já podemos aplicar uma transformação para um formato de arquivo de maior desempenho, como por exemplo o Parquet para trabalhar no ADLS.
Aqui, literalmente os dados são mantidos de forma provisória e após a transformação com sucesso dos dados para a Bronze, podem ser excluídos desta primeira camada.
🥉 Bronze (raw)
É a camada onde será armazenado os dados em seu formato bruto (As-Is), onde são derivadas da camada Transient e que após uma primeira carga, pode ser aplicado uma carga incremental dos dados utilizando o formato Delta.
Neste nível, normalmente quem têm acesso são os engenheiros de dados, mas a depender do objetivo do negócio, pode-se também ser aplicado análises por cientistas de dados que precisam realizar análises nos dados ainda em seu formato bruto para gerar alguns determinados insights mais específicos sem nenhum tratamento prévio.
🥈 Silver (trusted/acurated)
A ideia desta camada é transformar os dados brutos descentralizados, em entidades centralizadas, aplicando mais “desnormalização” nos dados. Logo, é aplicado diversas transformações, uniões, enriquecimento dos dados, aplicação de SCD, padronização e Data Quality, melhorando por exemplo nomenclatura dos campos (ex: inglês para português, retirada de abreviações – nm_cli = nome_cliente) conforme regras definidas pelo equipe envolvida na modelagem desta camada.
Nesta camada, saímos de uma visão de sistema para uma visão de negócio, realizando agrupamento de várias tabelas para transformar em uma entidade de negócio. Digamos que temos uma tabela chamada “Produtos” e “Produtos_Categorias, Produtos_Classes, Produtos_Fornecedores), aqui unificaríamos estas tabelas para formar uma entidade “Produto” que receberá vários atributos, tratando-os de uma forma que os dados fiquem mais contextualizados e qualificados. Poderá acontecer também de unificar uma mesma tabela do mesmo assunto, de diferentes sistemas. Ex: unificação de tabela do ERP chamada “Produtos” e E-commerce com tabela “Produtos”, formando uma única fonte de dados, podendo incluir um campo de “origem” para saber de que fonte de dados se trata o mesmo.

🥇 Gold (refined)
Finalmente, na camada Gold, é onde os dados deverão ser transformados e preparados para consumo pela área de negócio, ou seja, aqui poderemos aplicar mais uma camada de regras extras, separar determinados dados num escopo por área da organização, realizar a criação de tabelas com modelagem Star Schema (Fato e Dimensão), com agregações, cálculos, indicadores, com o enriquecimento de dados necessário e preparados para atingir um objetivo específico. Esta é uma camada às vezes “polêmica”, pois existem pessoas e negócios que tratam de formas diferentes, como por exemplo, uns modelam baseado no Star Schema, outros podem gerar OBT’s (One Big Tables) pois em alguns casos irão obter melhor performance na ferramenta de visualização, outros podem transformar os dados da Bronze para a Gold, etc…
Cada caso será “um caso” e muitas vezes podem acabar fugindo dos padrões para atender às necessidades do negócio. Porém, é preciso ter atenção durante a criação da estratégia e definição desta arquitetura, criar documentações, aplicar uma boa governança de dados, para que de fato, o seu Lakehouse mesmo com todas essas definições técnicas e preocupações, não acabe se tornando um data swamp (se não for bem acompanhado e gerenciado). Afinal de contas, não basta simplesmente planejar e criar, também é imprescindível monitorar e melhorar os processos (lembra do PDCA?).
Os dados hoje em dia não são apenas “o novo petróleo”, eles são tudo de mais valioso que uma empresa tem, se ela souber identificá-los, gerenciá-los e usar a seu favor, se tornará uma organização de grande referência no mercado perante aos seus concorrentes, utilizando-os com inteligência para reduzir seus custos e aumentar então o seu ROI.

🎯 Considerações finais
Este artigo foi criado com base em muito estudo a partir das referências que deixarei citados abaixo; são materiais que gosto bastante de ler, pois de fato são muito bons… vale a pena abrir cada um e realizar uma leitura deles para complemento. Alguns serão extremamente técnicos, por isso resolvi criar meu artigo trazendo em uma linguagem mais clara e direta para rápido entendimento de todos que lerem.
Referências:
What is a Medallion Architecture? (databricks.com)
Data Lake Zones: O que é? Para que serve? Quantas são? Quanto Custa? (linkedin.com)
3 camadas para sucesso do meu Data Lake (linkedin.com)
Fundamentos do Delta Lake (linkedin.com)
Evolution to the Data Lakehouse – The Databricks Blog
Festival da Tecnologia – YouTube
Até o próximo post, pessoal! #SimboraNavegarNosDados
Se você chegou até aqui, parabéns! Acabei de gerar mais dados na internet e, se você gostou, gere mais dados também curtindo e compartilhando este conteúdo. 😄
Sigam nossas redes sociais:
Avalie o nosso conteúdo:
